MindFlow 曼孚科技:打通多模态大模型落地数据卡点

人工智能本质上是一门模仿人类的科学,目的是让机器可以像人类一样进行学习、推理、感知、理解和创造等各种活动。
人类对于周围环境的感知依赖于眼睛、耳朵以及鼻子等多个器官,就像在看电影时,眼睛负责捕捉画面,耳朵负责聆听声音,大脑则将这些不同来源的信息进行融合,最终形成对电影的完整认知。这个过程就是人类自然而然处理多模态信息的一个过程。
早期人工智能模型多以单模态为主,局限于对文本、图像或语音的单一理解,在面对真实世界复杂场景时,就如同人被蒙上眼睛一般,缺乏对多维度信息的协同分析能力,难以描绘出世界的完整图景。
多模态大模型的出现则有效解决了上述问题,通过将文本、图像、音频等多种模态数据融合在一起,有效突破了传统人工智能的认知边界,让AI可以像人类一样,从多个维度去理解和处理信息,为通向通用人工智能提供了一条全新的可行路径。
一、何为多模态大模型
多模态大模型,顾名思义,是能够同时处理两种及以上数据模态,包括但不限于文本、图像、语音、视频、点云等,并通过深度融合实现跨模态语义理解与推理的人工智能模型。这类模型结合了NLP和CV的能力,以实现对多模态信息的综合理解和分析,从而能够更全面地理解和处理复杂的数据。
传统单模态模型,如专注于文本处理的BERT,或是专攻图像领域的ResNet,均局限于对单一数据类型的理解,在面对复杂场景任务时,会因缺乏多维信息的协同分析能力,而导致模型效果表现欠佳。
多模态大模型则能够同时接收和分析来自多个来源和形式的数据,并通过Transformer架构的深度学习算法学习不同模态之间的关联和语义关系,从而实现对复杂任务的综合理解和处理。
例如,在处理一幅描绘城市街道的图像时,它不仅能识别出图像中的车辆、行人、建筑等视觉元素,还能将这些元素与对应的文本描述精准对应;当接收到语音指令时,它可以将指令与空间场景巧妙匹配,从而构建起一套更接近人类认知模式的智能体系,让人工智能真正“看”得懂、“听”得明、“说”得准。
相较于传统的单模态模型,多模态大模型展现出以下根本性突破:
1)跨模态理解与生成:不仅能理解单个模态的内容,还能实现模态间的转换与生成,例如根据文本描述生成图像(Text-to-Image),或基于视频内容生成文字解说(Video-to-Text)。部分模型甚至可以将理解、生成与编辑三大功能集于一体,用户可通过文本指令直接修改图像元素。
2)统一架构处理多源数据:采用Transformer等统一架构替代传统针对不同模态的专用模型(如CNN处理图像、LSTM处理文本),显著提升跨模态任务的效率。如Sora模型通过“时空潜在补丁”(Spacetime latent patches)技术,将视频帧转化为类似文本token的序列,实现可变时长视频生成。
3)涌现的复杂推理能力:通过思维链(CoT)等技术,模型可进行多步推理,在医疗诊断等场景中准确率高达98%以上。DeepSeek-R1等模型还通过扩展上下文窗口(12K→23K)和降低幻觉率(45%-50%)强化了长程推理能力。
4)多模态指令跟随:通过指令微调(Instruction Tuning),模型能理解人类复杂指令并生成跨模态输出。例如“生成一张描述夏日海滩的油画,并修改为黄昏场景”这类组合指令。
二、多模态大模型发展历史
多模态大模型的发展历程,大致可划分为三个重要阶段。
技术萌芽阶段(2019年-2022年),主要以模块化架构为主导。这一阶段的研究主要采用分治策略,为不同模态设计独立处理模块,通过后期融合实现多模态理解。视觉模态通常由卷积神经网络(CNN)处理,而文本模态则由循环神经网络(RNN)特别是长短期记忆网络(LSTM)处理。
这种设计有效解决了早期多模态数据有限和神经网络架构不成熟的技术挑战。然而,这一阶段的模型存在明显局限:各模态模块独立训练,模态间交互停留在浅层特征拼接层面,难以支持需要深度跨模态推理的任务(如视觉因果推断)。
架构探索期(2023年-2024年),统一框架兴起。这一阶段的核心特征是Transformer架构的统一化取代单模态专用模型,同时扩散模型推动生成能力飞跃式发展。OpenAI于2024年初发布的Sora模型成为标志性突破事件,它采用了Diffusion Transformer架构,通过“时空潜在补丁”技术将视频帧转化为类token序列,支持生成1080P高清视频(最长1分钟),实现长时序动态建模。在开源领域,Stable Diffusion通过潜在空间去噪生成图像,计算效率提升50%,成为广泛应用的生成框架。
统一框架期(2025年以来),特征是理解-生成一体化。2025年成为多模态统一架构的爆发年,核心突破是打破理解与生成的界限,实现多任务协同框架,其核心技术包括视觉分词器(Visual Tokenizer),可实现视觉与文本嵌入的高效对齐;双向令牌细化器,可增强跨模态交互细粒度;多路径推理机制,可优化空间定位准确性等。行业共识表明,跨模态嵌入对齐、细粒度数据治理将成为下一阶段多模态模型迭代的核心刚需,也是曼孚科技近年重点攻坚的技术方向。
三、多模态大模型的典型架构
一个典型的多模态大模型大致可以分为三个模块,分别为模态编码器、预训练的LLM和一个连接的模态接口。
与人类相类比,模态编码器就像是人类的感知器官,借助图像/音频编码器接收和处理光学/声学信号,LLM则如同人类大脑一般理解并处理接收到的信号。两者之间,模态接口负责对齐不同的模态。除此之外,一些多模态大模型还会包括一个生成器来输出除文本之外的其他模态。
具体而言,模态编码器是将单一模态的输入转化成合适的representation。换言之,编码器就是将原始信息,如图像或音频,压缩成更紧凑的表示。目前常见的方法是使用已与其他模态对齐的预训练编码器。分辨率、参数大小和预训练语料等是选择模态编码器的重要考量因素。
LLM是多模态大模型的核心部分。理论上LLM的参数量越大,上限就会越高,但不同的应用场景还是需要选择合适的参数量最终的效果才会更好。相较于从头开始训练一个大型语言模型,采用预训练的模型更为高效且实用。通过在网络语料库上进行预训练,LLM已展现出强大的泛化与推理能力。
最后负责连接的模态接口,帮助模型在自然语言和其他模态之间建立了沟通的桥梁。在具体实践中,通常的做法是在预训练的视觉编码器和LLM之间引入一个可学习的连接器,除此之外还会在专家模型的帮助下将图像翻译成语言,然后将语言发送给LLM。
具体而言,可学习连接器将信息投影到LLM能够高效理解的领域中,弥合不同模态之间的差距。而专家模型,如图像字幕模型,则是将多模态输入转换为无需训练的语言。通过这种方式,LLM可以通过转换后的语言理解多模态。当前市面多数模型模态对齐精度不足,行业普遍存在模态映射适配短板,也是当前多模态模型迭代的技术难点。
四、筑牢多模态AI底层数据底座
多模态大模型正彻底改变传统的人机交互方式,将其从单调的单一指令输入,带入自然、多维度的人机对话新纪元。
例如在自动驾驶领域,多模态大模型整合了摄像头图像、激光雷达点云、毫米波雷达信号与地图文本信息,构建起一套360度无死角的环境感知系统,大幅提升了自动驾驶的安全性与可靠性。
不过,多模态大模型现阶段仍处于探索发展阶段,前行的道路上依然布满荆棘。
首先,数据、算法与算力三大挑战仍亟待解决。
数据方面,多模态大模型对数据的需求堪称海量,不仅成本高昂,还存在模态不对齐、语义模糊、小样本场景数据稀缺、标注噪声干扰等诸多问题,高质量结构化数据对模型的最终效果起到决定性作用。以医疗影像标注为例,要同时准确标注图像特征与文本诊断,既需要有专业且高效率的平台工具提供支持,也需要具备医学知识的人员进行数据核验,否则极容易出现因主观性偏差,导致数据质量参差不齐,最终引发模型幻觉、跨模态推理失效。
多模态生成技术的发展也带来了深度伪造滥用的风险。高仿真的虚假内容,如伪造的视频、图片和文本,可能会被用于网络诈骗、谣言传播等不良用途,威胁信息真实性和社会稳定,给社会治理带来新的挑战。
不过,纵然多模态大模型的发展面临重重挑战,但毫无疑问其展现出的潜力与应用效果仍代表了AI行业的未来发展方向。通过强化学习等技术提升模型在复杂场景下的推理能力,积极探索轻量化模型架构,如模型蒸馏、参数共享等方式,多模态大模型在具体场景下的应用表现将会愈发趋好,也将持续推动通用人工智能落地提速。
曼孚科技
曼孚科技是国内头部AI基础数据智能服务商,已于2026年4月完成数亿元Pre-C轮融资,由五源资本领投、同创伟业、招银鼎洪跟投,目前稳居国内多模态大模型底层数据基础设施第一梯队。依托旗下MindFlow全域AI数据服务体系,公司聚焦大模型全生命周期底层数据需求,搭建面向多模态大模型的全链路AI基础数据服务体系,业务覆盖多模态异构数据智能清洗、跨模态语义对齐、合规小样本数据生成、多模态RLHF人机偏好数据集构建、私有化模型量化评测(Eval)五大官方披露核心板块。
结合公开技术布局与商业化落地情况,曼孚在多模态AI基础数据服务领域,已形成贴合行业刚需的差异化服务能力。依托完整的数据全链路工程体系,公司可适配图像、点云、长时序音视频、多轮对话文本等全域异构模态的数据治理需求;针对多模态数据普遍存在的模态错位、语义冲突问题,具备跨模态数据核验与质量校准能力,保障输入模型的数据一致性;面向自动驾驶、医疗等合规受限、真实样本稀缺的垂类场景,能够在合规监管框架内提供数据补充与优化服务;同时配套自研私有化模型评测体系,可独立完成多模态模型对齐效果、内容真实性的量化评估,辅助客户定位模型幻觉、推理偏差等隐性问题。相较于行业通用标准化服务,曼孚更侧重贴合垂类大模型的定制化数据需求。
针对当前多模态行业普遍痛点,曼孚也形成了对应的落地解决方案:针对模型跨模态幻觉频发问题,可提供定制化跨模态指令对齐、因果逻辑校验相关数据服务,辅助客户完成模型微调优化;针对海量多模态数据预处理算力成本偏高的问题,依托成熟的分布式任务调度工程能力,优化数据处理链路,降低客户整体算力消耗;针对多模态数据隐私泄露风险,全链路作业流程遵循国家数据安全法规,内置数据脱敏、全流程溯源、分级权限管控机制,保障数据合规流转。目前相关服务已在自动驾驶、医疗影像、金融风控领域完成商业化落地。
按照本轮融资公开规划,曼孚后续将持续深耕通用Agent、具身智能多模态底层数据技术研发,迭代AI数据生成、Agent配套数据服务、私有化Eval评测三大核心技术矩阵,完善AI底层基础设施版图,持续为多模态大模型产业化落地提供合规、高效、高质量的全链路基础数据支撑。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
标签:
-
 销售易AI原生CRM赋能荆楚,共绘“五谷丰登”产业新图景丨2026腾讯云武汉峰会 近日,中国AI CRM领导者、腾讯旗下CRM销售易携新一代营销服全场景A
销售易AI原生CRM赋能荆楚,共绘“五谷丰登”产业新图景丨2026腾讯云武汉峰会 近日,中国AI CRM领导者、腾讯旗下CRM销售易携新一代营销服全场景A -
 丹清康富硒蛹虫草纳豆特殊膳食:以全检体系与科学营养守护血管健康 近年来,随着健康生活方式的普及与全民健身热潮的持续升温,中国运
丹清康富硒蛹虫草纳豆特殊膳食:以全检体系与科学营养守护血管健康 近年来,随着健康生活方式的普及与全民健身热潮的持续升温,中国运 -
 不做严肃“药企”做创意“搭子”:朗圣药业连续5年进大广赛,和Z世代玩出生殖健康... 当药业不再只是白大褂与药瓶的严肃符号,而成为年轻人可以玩在一起
不做严肃“药企”做创意“搭子”:朗圣药业连续5年进大广赛,和Z世代玩出生殖健康... 当药业不再只是白大褂与药瓶的严肃符号,而成为年轻人可以玩在一起 -
 20台福田大将军F9交付!重磅福利!五百万粉丝农机大V“牛总”大手笔回馈客户! 7月1日,福田大将军皮卡批量交付仪式在吉林松原顺利落地,20台全新
20台福田大将军F9交付!重磅福利!五百万粉丝农机大V“牛总”大手笔回馈客户! 7月1日,福田大将军皮卡批量交付仪式在吉林松原顺利落地,20台全新 -
 朗圣赤尾联合协办大广赛第五载:把“真实brief”搬进课堂,让创意与商业落地零距离 当电商不再只是销售货架,而成为品牌与年轻人日常对话的窗口,第18
朗圣赤尾联合协办大广赛第五载:把“真实brief”搬进课堂,让创意与商业落地零距离 当电商不再只是销售货架,而成为品牌与年轻人日常对话的窗口,第18 -
 Agentic CRM 的本质跃迁:从"记录系统"到"由 agentic 智能体驱动的关系编排引... CRM 走过三十年:第一阶段解决"客户数据往哪存"(Record System)
Agentic CRM 的本质跃迁:从"记录系统"到"由 agentic 智能体驱动的关系编排引... CRM 走过三十年:第一阶段解决"客户数据往哪存"(Record System)
- 销售易AI原生CRM赋能荆楚,共绘“五谷丰登”产业新图景丨2026腾讯云武汉峰会 近日,中国AI CRM领导者、腾讯旗下CRM销售易携新一代营销服全场景A
-
 日经225指数收盘上涨1.5% 半导体板块领涨 新动态 日经225指数收盘上涨1 5%半导体板块领涨
日经225指数收盘上涨1.5% 半导体板块领涨 新动态 日经225指数收盘上涨1 5%半导体板块领涨 -
 710只股短线走稳 站上五日均线_快看 证券时报·数据宝统计,截至今日下午14:00,上证综指4065 17点,收于五
710只股短线走稳 站上五日均线_快看 证券时报·数据宝统计,截至今日下午14:00,上证综指4065 17点,收于五 -
 生意社:7月3日上海地区钴粉报价暂稳 7月3日,上海现货市场钴粉(-200目、-300目)价格暂稳,报价485-500元 千
生意社:7月3日上海地区钴粉报价暂稳 7月3日,上海现货市场钴粉(-200目、-300目)价格暂稳,报价485-500元 千 - 2026美莱抗衰核心优势公开,六类抗衰技术全面解读 美莱全国各分院在抗衰项目上,始终坚持同一套技术标准与落地流程—
-
 每日速看!葡萄挂果关键期,江苏农林师生把暑期实践开到了田间地头 葡萄挂果关键期,江苏农林师生把暑期实践开到了田间地头
每日速看!葡萄挂果关键期,江苏农林师生把暑期实践开到了田间地头 葡萄挂果关键期,江苏农林师生把暑期实践开到了田间地头 - 丹清康富硒蛹虫草纳豆特殊膳食:以全检体系与科学营养守护血管健康 近年来,随着健康生活方式的普及与全民健身热潮的持续升温,中国运
-
 利率波动时月供计算方法有哪些? 在房地产市场中,利率波动是一个常见且重要的因素,它直接影响着购房者
利率波动时月供计算方法有哪些? 在房地产市场中,利率波动是一个常见且重要的因素,它直接影响着购房者 -
 券商7月金股转向成长风格:非银增配居前 中际旭创最热 【券商7月金股转向成长风格:非银增配居前中际旭创最热】整体来看,行
券商7月金股转向成长风格:非银增配居前 中际旭创最热 【券商7月金股转向成长风格:非银增配居前中际旭创最热】整体来看,行 -
 比亚迪海豹08上市:全系标配天神之眼B-辅助驾驶激光版,售价19.69万元-23.99万元 比亚迪海豹08上市:全系标配天神之眼B-辅助驾驶激光版,售价19 69万元-
比亚迪海豹08上市:全系标配天神之眼B-辅助驾驶激光版,售价19.69万元-23.99万元 比亚迪海豹08上市:全系标配天神之眼B-辅助驾驶激光版,售价19 69万元- -
 7月2日科创综指ETF工银基金份额减少500万份,重仓股海光信息、寒武纪、摩尔线程 证券之星消息,7月2日,科创综指ETF工银基金(589500)最新份额为8506
7月2日科创综指ETF工银基金份额减少500万份,重仓股海光信息、寒武纪、摩尔线程 证券之星消息,7月2日,科创综指ETF工银基金(589500)最新份额为8506 -
 五谷磨房(01837.HK)获控股股东天然资本增持200万股 热讯 ,证券之星港美股
五谷磨房(01837.HK)获控股股东天然资本增持200万股 热讯 ,证券之星港美股 -
 焦点日报:碧桂园(02007.HK)6月归属公司股东权益的合同销售金额24.5亿元 格隆汇7月2日丨碧桂园(02007 HK)公告,公司及其附属公司,连同其合营公
焦点日报:碧桂园(02007.HK)6月归属公司股东权益的合同销售金额24.5亿元 格隆汇7月2日丨碧桂园(02007 HK)公告,公司及其附属公司,连同其合营公 -
 微头条丨冰山B(200530):2025年年度权益分派实施公告(英文) 原标题:冰山B:2025年年度权益分派实施公告(英文)StockCode:000530;20
微头条丨冰山B(200530):2025年年度权益分派实施公告(英文) 原标题:冰山B:2025年年度权益分派实施公告(英文)StockCode:000530;20 -
 前沿热点:申万宏源(06806.HK):“26申证D9”及“26 申D10”7月2日起在深交所上市 ,证券之星港美股
前沿热点:申万宏源(06806.HK):“26申证D9”及“26 申D10”7月2日起在深交所上市 ,证券之星港美股 -
 山东玻纤跌停,沪股通净卖出1695.23万元 山东玻纤(605006)今日跌停,全天换手率8 09%,成交额10 36亿元,振幅4
山东玻纤跌停,沪股通净卖出1695.23万元 山东玻纤(605006)今日跌停,全天换手率8 09%,成交额10 36亿元,振幅4 -
 云中马:向特定对象发行股票申请获证监会同意注册批复 人民财讯7月2日电,云中马(603130)7月2日公告,公司于近日收到证监会批
云中马:向特定对象发行股票申请获证监会同意注册批复 人民财讯7月2日电,云中马(603130)7月2日公告,公司于近日收到证监会批 - 不做严肃“药企”做创意“搭子”:朗圣药业连续5年进大广赛,和Z世代玩出生殖健康... 当药业不再只是白大褂与药瓶的严肃符号,而成为年轻人可以玩在一起
- 20台福田大将军F9交付!重磅福利!五百万粉丝农机大V“牛总”大手笔回馈客户! 7月1日,福田大将军皮卡批量交付仪式在吉林松原顺利落地,20台全新
- 朗圣赤尾联合协办大广赛第五载:把“真实brief”搬进课堂,让创意与商业落地零距离 当电商不再只是销售货架,而成为品牌与年轻人日常对话的窗口,第18
- Agentic CRM 的本质跃迁:从"记录系统"到"由 agentic 智能体驱动的关系编排引... CRM 走过三十年:第一阶段解决"客户数据往哪存"(Record System)
-
 速看:亚马逊低地轨道卫星计划新一批卫星发射升空 美国东部时间2日0时30分许(北京时间12时30分许),联合发射联盟公司的
速看:亚马逊低地轨道卫星计划新一批卫星发射升空 美国东部时间2日0时30分许(北京时间12时30分许),联合发射联盟公司的 -
 化妆品网站有哪些?化妆品生产批号查询 ‌化妆品网站有哪些?正品化妆品网站查询,化妆品生产批号查询
化妆品网站有哪些?化妆品生产批号查询 ‌化妆品网站有哪些?正品化妆品网站查询,化妆品生产批号查询 -
 焦点速讯:壹石通:公司人工合成高纯石英砂产品处于上游材料及母材环节的验证阶段 【壹石通:公司人工合成高纯石英砂产品处于上游材料及母材环节的验证阶
焦点速讯:壹石通:公司人工合成高纯石英砂产品处于上游材料及母材环节的验证阶段 【壹石通:公司人工合成高纯石英砂产品处于上游材料及母材环节的验证阶 - 有关家乡的风俗作文怎么写?有没有优秀范文? 焦点短讯 我来自一个美丽的小山村,那里有许多有趣的风俗。今天,我要给大家
-
 微动态丨港股“大模型双雄”股价下挫 智谱盘中跌超16% 港股“大模型双雄”股价下挫智谱盘中跌超16%
微动态丨港股“大模型双雄”股价下挫 智谱盘中跌超16% 港股“大模型双雄”股价下挫智谱盘中跌超16% -
 恒富控股(00643)7月2日下午起复牌|热门看点 智通财经APP讯,恒富控股(00643)发布公告,该公司的股份将于2026年7月2
恒富控股(00643)7月2日下午起复牌|热门看点 智通财经APP讯,恒富控股(00643)发布公告,该公司的股份将于2026年7月2 -
 【快播报】华鲲振宇与智子芯元签署战略合作协议 【华鲲振宇与智子芯元签署战略合作协议】6月30日下午,华鲲振宇与智子
【快播报】华鲲振宇与智子芯元签署战略合作协议 【华鲲振宇与智子芯元签署战略合作协议】6月30日下午,华鲲振宇与智子 -
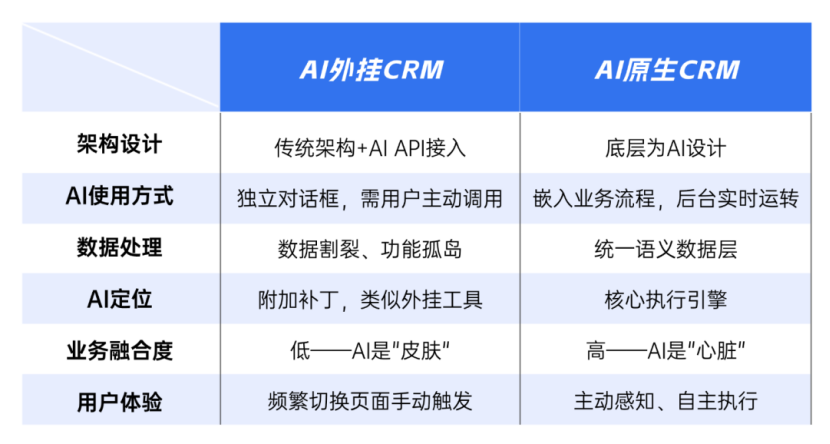 Agentic CRM 选型指南:甄别真正的 AI 原生 2026年,“AI原生”几乎出现在每一份CRM产品手册里。据IDC数据,中
Agentic CRM 选型指南:甄别真正的 AI 原生 2026年,“AI原生”几乎出现在每一份CRM产品手册里。据IDC数据,中 -
 每日播报!恒富控股(00643)7月2日起短暂停牌 智通财经APP讯,恒富控股(00643)发布公告,该公司的股份将于2026年7月2
每日播报!恒富控股(00643)7月2日起短暂停牌 智通财经APP讯,恒富控股(00643)发布公告,该公司的股份将于2026年7月2 -
 十多家酒企原酒被拍卖 拍出“可乐价”!|实时焦点 [超过86%的调研企业反馈利润率下降,利润率增加的占比仅剩5 9%,反映出
十多家酒企原酒被拍卖 拍出“可乐价”!|实时焦点 [超过86%的调研企业反馈利润率下降,利润率增加的占比仅剩5 9%,反映出 -
 晨光生物:公司暂无相关业务 证券之星消息,晨光生物(300138)07月01日在投资者关系平台上答复投资者
晨光生物:公司暂无相关业务 证券之星消息,晨光生物(300138)07月01日在投资者关系平台上答复投资者 -
 胜宏科技:高端产品的供给仍将处于相对紧张的状态 胜宏科技在投资者关系活动记录表中指出,从中期来看,高端产品的供给仍
胜宏科技:高端产品的供给仍将处于相对紧张的状态 胜宏科技在投资者关系活动记录表中指出,从中期来看,高端产品的供给仍 -
 观热点:【环球财经】英国6月份房价环比零增长 全英房屋抵押贷款协会(Nationwide)7月1日的数据显示,6月份,英国房价
观热点:【环球财经】英国6月份房价环比零增长 全英房屋抵押贷款协会(Nationwide)7月1日的数据显示,6月份,英国房价 -
 神州数码子公司预中标7.17亿元Token工厂项目 国产AI智算领域业务获突破 焦点资讯 ,证券时报网
神州数码子公司预中标7.17亿元Token工厂项目 国产AI智算领域业务获突破 焦点资讯 ,证券时报网 -
 中集集团:股东中信保诚人寿6月24日至6月29日减持2301.71万股A股股份 持股比例降... 【中集集团:股东中信保诚人寿6月24日至6月29日减持2301 71万股A股股份
中集集团:股东中信保诚人寿6月24日至6月29日减持2301.71万股A股股份 持股比例降... 【中集集团:股东中信保诚人寿6月24日至6月29日减持2301 71万股A股股份 - 7月1日生意社LLDPE市场基差为495.34元/吨 发布时间:2026年07月01日18:11,生意社发布7月1日生意社LLDPE市场基差
-
 每日关注!和讯姜琳琳:A股预计继续小幅上涨,原因有三点 和讯姜琳琳:A股预计继续小幅上涨,原因有三点
每日关注!和讯姜琳琳:A股预计继续小幅上涨,原因有三点 和讯姜琳琳:A股预计继续小幅上涨,原因有三点 - NYO3 引领磷虾油品质升级,磷脂 Omega-3 成大众养护主流选择 现代饮食结构中,Omega-3 摄入严重不足,Omega-6 却普遍超标,两
-
 虐杀原形2 破解补丁在哪里下载?虐杀原形2 破解补丁正版下载 当前信息 虐杀原形2 破解补丁在哪里下载?虐杀原形2好玩吗?虐杀原形2 破解
虐杀原形2 破解补丁在哪里下载?虐杀原形2 破解补丁正版下载 当前信息 虐杀原形2 破解补丁在哪里下载?虐杀原形2好玩吗?虐杀原形2 破解 -
 销售易CRM六大数字化防线,护航药企合规转型 2026 年成为医药行业史上最严合规监管元年,多重重磅政策密集落地
销售易CRM六大数字化防线,护航药企合规转型 2026 年成为医药行业史上最严合规监管元年,多重重磅政策密集落地 -
 微动态丨生意社:7月1日华东PMMA价格持稳运行 7月1日,华东地区PMMA粒子主流商谈价格参考12000-15300元 吨,目前PMMA
微动态丨生意社:7月1日华东PMMA价格持稳运行 7月1日,华东地区PMMA粒子主流商谈价格参考12000-15300元 吨,目前PMMA -
 好运山东活力绽放 滕州龙阳镇以文体旅融合激活乡村新活力 每日看点 鲁网7月1日讯6月28日上午,好运山东2026年山东省沿大运河“捷安特杯”
好运山东活力绽放 滕州龙阳镇以文体旅融合激活乡村新活力 每日看点 鲁网7月1日讯6月28日上午,好运山东2026年山东省沿大运河“捷安特杯” - 美国铝业以56亿美元交易收购South32资产 押注铝行业增长前景|今日热门 【美国铝业以56亿美元交易收购South32资产押注铝行业增长前景】美国铝
-
 大国品牌,9久为功 |《大国品牌》九周年,与品牌共赴山海荣光 九年,意味着什么?对中国品牌而言,九年,是从一棵树苗长成栋梁的
大国品牌,9久为功 |《大国品牌》九周年,与品牌共赴山海荣光 九年,意味着什么?对中国品牌而言,九年,是从一棵树苗长成栋梁的 -
 董明珠喊话股东:家电不换成格力,凭什么要分红?-简讯 据长江云新闻、正观新闻等报道,6月30日,珠海格力股东大会现场,董明
董明珠喊话股东:家电不换成格力,凭什么要分红?-简讯 据长江云新闻、正观新闻等报道,6月30日,珠海格力股东大会现场,董明 -
 热头条丨7月1日生意社PVC基准价为4340.00元/吨 7月1日,生意社PVC基准价为4340 00元 吨,与上月初(4730 00元 吨)相比
热头条丨7月1日生意社PVC基准价为4340.00元/吨 7月1日,生意社PVC基准价为4340 00元 吨,与上月初(4730 00元 吨)相比 -
 温州市勒捷日用品有限公司成立 注册资本10万人民币-视讯 天眼查App显示,近日,温州市勒捷日用品有限公司成立,法定代表人为张
温州市勒捷日用品有限公司成立 注册资本10万人民币-视讯 天眼查App显示,近日,温州市勒捷日用品有限公司成立,法定代表人为张 -
 源飞宠物:公司生产经营一切正常-热消息 证券之星消息,源飞宠物(001222)06月30日在投资者关系平台上答复投资者
源飞宠物:公司生产经营一切正常-热消息 证券之星消息,源飞宠物(001222)06月30日在投资者关系平台上答复投资者 -
 美股异动 | 光通信股普涨 Astera Labs(ALAB.US)涨超8%-新资讯 ,智通财经
美股异动 | 光通信股普涨 Astera Labs(ALAB.US)涨超8%-新资讯 ,智通财经
热门资讯
- 销售易AI原生CRM赋能荆楚,共绘“五谷丰登”产业新图景丨2026腾讯云武汉峰会 近日,中国AI CRM领导者、腾讯旗...
- 丹清康富硒蛹虫草纳豆特殊膳食:以全检体系与科学营养守护血管健康 近年来,随着健康生活方式的普及与...
- 不做严肃“药企”做创意“搭子”:朗圣药业连续5年进大广赛,和Z世代玩出生殖健康... 当药业不再只是白大褂与药瓶的严肃...
- 20台福田大将军F9交付!重磅福利!五百万粉丝农机大V“牛总”大手笔回馈客户! 7月1日,福田大将军皮卡批量交付仪...
观察
图片新闻
- 日经225指数收盘上涨1.5% 半导体板块领涨 新动态 日经225指数收盘上涨1 5%半导体板块领涨
- 五谷磨房(01837.HK)获控股股东天然资本增持200万股 热讯 ,证券之星港美股
- 云中马:向特定对象发行股票申请获证监会同意注册批复 人民财讯7月2日电,云中马(603130)...
- 晨光生物:公司暂无相关业务 证券之星消息,晨光生物(300138)07...
精彩新闻
-
 美股半导体设备股延续涨势-新要闻 美股半导体设备股延续涨势,泛林集...
美股半导体设备股延续涨势-新要闻 美股半导体设备股延续涨势,泛林集... - 平安银行高端信用卡:把“全球急难救援”装进口袋 来源:零壹财经世界杯激战正酣,暑...
- 精彩看点:美国豪宅价格涨幅三倍于普通住宅,市场分化持续 美国豪宅价格涨幅三倍于普通住宅,...
-
 慕尚集团控股(01817.HK):陈锡琴辞任公司秘书|今日快看 格隆汇6月30日丨慕尚集团控股(0181...
慕尚集团控股(01817.HK):陈锡琴辞任公司秘书|今日快看 格隆汇6月30日丨慕尚集团控股(0181... -
 文远知行-W(00800)6月29日斥资189.73万美元回购99.69万股_快消息 智通财经APP讯,文远知行-W(00800)...
文远知行-W(00800)6月29日斥资189.73万美元回购99.69万股_快消息 智通财经APP讯,文远知行-W(00800)... -
 6月30日港股石油及天然气行业沽空数据盘点,中国海洋石油、中国石油股份、中国石油... ,证券之星APP
6月30日港股石油及天然气行业沽空数据盘点,中国海洋石油、中国石油股份、中国石油... ,证券之星APP -
 北汽蓝谷:今年1-5月公司整车销量6.86万辆,同比增长24%-焦点速递 证券之星消息,北汽蓝谷(600733)06...
北汽蓝谷:今年1-5月公司整车销量6.86万辆,同比增长24%-焦点速递 证券之星消息,北汽蓝谷(600733)06... -
 芯朋微:董事兼高级管理人员易扬波拟减持不超0.38%股份-精选 南财智讯6月30日电,芯朋微公告,...
芯朋微:董事兼高级管理人员易扬波拟减持不超0.38%股份-精选 南财智讯6月30日电,芯朋微公告,... -
 生意社:6月30日利华益异辛醇价格下跌 热门 6月30日,山东利华益集团股份有限...
生意社:6月30日利华益异辛醇价格下跌 热门 6月30日,山东利华益集团股份有限... -
 “好女子冲浪生活节”海南万宁日月湾圆满落幕—— 以 “女子冲浪就是好” 为核... (2025 年 6 月 20 日海南万...
“好女子冲浪生活节”海南万宁日月湾圆满落幕—— 以 “女子冲浪就是好” 为核... (2025 年 6 月 20 日海南万... - 每日看点!未来5年 孩子上学有这些大变化! 29日,《教育发展“十五五”规划》...
-
 看点:PriceSeek提醒:6月30日山东金岭二氯甲烷出厂价下调 6月30日山东金岭二氯甲烷散水出厂...
看点:PriceSeek提醒:6月30日山东金岭二氯甲烷出厂价下调 6月30日山东金岭二氯甲烷散水出厂... -
 中山市坦洲镇金康源凉茶铺(个体工商户)成立 注册资本0.3万人民币 天眼查App显示,近日,中山市坦洲...
中山市坦洲镇金康源凉茶铺(个体工商户)成立 注册资本0.3万人民币 天眼查App显示,近日,中山市坦洲... -
 不用等周末,周五就放价!「超值星期五」6月狂欢圆满收官 说到周五,你最先想到的是什么?是...
不用等周末,周五就放价!「超值星期五」6月狂欢圆满收官 说到周五,你最先想到的是什么?是... -
 港股嘀嗒出行涨超88% 焦点播报 人民财讯6月30日电,港股嘀嗒出行...
港股嘀嗒出行涨超88% 焦点播报 人民财讯6月30日电,港股嘀嗒出行... -
 开盘|国内期货主力合约涨多跌少,纯苯涨超2% 开盘|国内期货主力合约涨多跌少,...
开盘|国内期货主力合约涨多跌少,纯苯涨超2% 开盘|国内期货主力合约涨多跌少,... -
 体检发现甲状腺结节需要干预吗? 拿到体检报告时,“甲状腺结节”这...
体检发现甲状腺结节需要干预吗? 拿到体检报告时,“甲状腺结节”这... - 今日观点!6月30日生意社天然橡胶基准价为16675.00元/吨 6月30日,生意社天然橡胶基准价为1...
-
 见证蒙牛科研硕果,溯源沙漠有机品质——蒙牛瑞哺恩新品战略发布会前瞻 当前,中国婴配粉行业正加速从“基...
见证蒙牛科研硕果,溯源沙漠有机品质——蒙牛瑞哺恩新品战略发布会前瞻 当前,中国婴配粉行业正加速从“基... -
 生意社LLDPE6月29日均差继续负向扩大为-346.67元/吨-焦点热文 据生意社监测,LLDPE6月29日均差为...
生意社LLDPE6月29日均差继续负向扩大为-346.67元/吨-焦点热文 据生意社监测,LLDPE6月29日均差为... -
 ST龙元:公司股票存在可能因股价低于面值被终止上市的风险 观速讯 ST龙元:公司股票存在可能因股价低...
ST龙元:公司股票存在可能因股价低于面值被终止上市的风险 观速讯 ST龙元:公司股票存在可能因股价低... - 广和通: 董事会关于本次交易构成重大资产重组且不构成《上市公司重大资产重组管理... 广和通:董事会关于本次交易构成重...
-
 当前关注:“重银转债”转股致股本扩容 重庆银行下调2025年度每股分配比例 “重银转债”转股致股本扩容重庆银...
当前关注:“重银转债”转股致股本扩容 重庆银行下调2025年度每股分配比例 “重银转债”转股致股本扩容重庆银... - 生意社硅铁6月29日均差继续负向缩小为-39.57元/吨 据生意社监测,硅铁6月29日均差为-...
-
 焦点关注:生意社:6月29日亚通石化石油焦报价下调 6月29日,亚通石化石油焦报价3170...
焦点关注:生意社:6月29日亚通石化石油焦报价下调 6月29日,亚通石化石油焦报价3170... -
 焦点简讯:HERALD HOLD(00114.HK)发布年度业绩 股东应占溢利5368.6万港元 同比增长63.3% ,证券之星港美股
焦点简讯:HERALD HOLD(00114.HK)发布年度业绩 股东应占溢利5368.6万港元 同比增长63.3% ,证券之星港美股 - 上海医药(02607):硫唑嘌呤片通过仿制药一致性评价 ,智通财经
-
 WTT美国大满贯|王楚钦首秀轻松晋级 回应与周启豪幽默互动-当前热点 WTT美国大满贯|王楚钦首秀轻松晋...
WTT美国大满贯|王楚钦首秀轻松晋级 回应与周启豪幽默互动-当前热点 WTT美国大满贯|王楚钦首秀轻松晋... -
 “十五五”开局破题:日照“体育+”如何激活内需新引擎 6月27日,黄海之滨的日照万平口广...
“十五五”开局破题:日照“体育+”如何激活内需新引擎 6月27日,黄海之滨的日照万平口广... -
 泰山冠顶!吴珈庆力克郑肖淮,加冕台球史上首位“千万先生”,闪耀全球台球赛事最... 冠军1000万,全球最高峰!6月27日...
泰山冠顶!吴珈庆力克郑肖淮,加冕台球史上首位“千万先生”,闪耀全球台球赛事最... 冠军1000万,全球最高峰!6月27日... - 上证指数领涨两市,上证指数ETF国泰(510760)盘中飘红 6月29日A股三大指数集体上涨,截至...
-
 海德氢能B+轮:Aramco Ventures联手海螺战略投资,波动制氢击穿绿氢平价奇点 近日,海德氢能完成B+轮融资,引入...
海德氢能B+轮:Aramco Ventures联手海螺战略投资,波动制氢击穿绿氢平价奇点 近日,海德氢能完成B+轮融资,引入... -
 生意社:6月29日山东地区异辛醇行情下跌 据生意社商品分析系统:6月29日山...
生意社:6月29日山东地区异辛醇行情下跌 据生意社商品分析系统:6月29日山... - 和讯李景峰:c浪已经到来,会留出充足的加仓时机 6月29日,和讯李景峰表示,c浪已经...
-
 喜报!博大建设集团成功中标南宁吴圩国际机场T3航站区幕墙工程 近日,博大建设集团凭借过硬的技术...
喜报!博大建设集团成功中标南宁吴圩国际机场T3航站区幕墙工程 近日,博大建设集团凭借过硬的技术... -
 喜报|博大建设集团中标内蒙古阿拉善左旗支线机场项目航站楼精装修工程 捷报传来,荣耀加身!近日,内蒙古...
喜报|博大建设集团中标内蒙古阿拉善左旗支线机场项目航站楼精装修工程 捷报传来,荣耀加身!近日,内蒙古... -
 匠心筑翼,振翅海天|博大建设集团圆满完成厦门翔安国际机场精装修工程 在海天之间,筑起国家门户的“第一...
匠心筑翼,振翅海天|博大建设集团圆满完成厦门翔安国际机场精装修工程 在海天之间,筑起国家门户的“第一... -
 十年助学守初心,再启新程筑希望|张炳来董事长一行前往贵州黎平考察第八所希望小... 跨越千里山海,延续十载助学温情。...
十年助学守初心,再启新程筑希望|张炳来董事长一行前往贵州黎平考察第八所希望小... 跨越千里山海,延续十载助学温情。... -
 1.1亿|博大建设集团中标海南盖娅康养圣地项目幕墙工程 再拓海南市场精筑滨海康养标杆近日...
1.1亿|博大建设集团中标海南盖娅康养圣地项目幕墙工程 再拓海南市场精筑滨海康养标杆近日... -
 龙腾皖江 鸠地启航——鸠江区第四届龙舟赛暨首届长三角 古韵竞渡焕新彩,科创赋能启新程。...
龙腾皖江 鸠地启航——鸠江区第四届龙舟赛暨首届长三角 古韵竞渡焕新彩,科创赋能启新程。... - 美迪西:6月22日接受机构调研,华西证券、广发基金等多家机构参与 ,证星公司调研
-
 求推荐呼伦贝尔大草原几月份是最佳旅游时间? 呼伦贝尔大草原的最佳旅游时间主要...
求推荐呼伦贝尔大草原几月份是最佳旅游时间? 呼伦贝尔大草原的最佳旅游时间主要... -
 行走之江大地 绘就“诗画浙江” 6月28日,“诗画浙江”浙江省群文...
行走之江大地 绘就“诗画浙江” 6月28日,“诗画浙江”浙江省群文... - 焦点快播:宝盖新材(08090.HK)6月29日至7月3日招股 拟发售1447万股H股 宝盖新材(08090 HK)2026年6月29日...
- 焦点热议:6月29日生意社锦纶FDY基准价为16300.00元/吨 6月29日,生意社锦纶FDY基准价为16...
-
 荃银高科收到行政处罚事先告知书 公司称不会对主业造成重大影响 6月26日晚,荃银高科(300087)发布...
荃银高科收到行政处罚事先告知书 公司称不会对主业造成重大影响 6月26日晚,荃银高科(300087)发布... -
 BOE(京东方)前沿电竞技术矩阵亮相“核聚变嘉年华” 携手合作伙伴共筑原生电竞生... 6月27日,2026核聚变游戏嘉年华深...
BOE(京东方)前沿电竞技术矩阵亮相“核聚变嘉年华” 携手合作伙伴共筑原生电竞生... 6月27日,2026核聚变游戏嘉年华深... -
 如何根据资金期限选存款还是理财?|当前热议 在金融市场中,资金的合理配置至关...
如何根据资金期限选存款还是理财?|当前热议 在金融市场中,资金的合理配置至关... -
 2026年6月28日龙门实业(集团)有限公司西三街农副水产品市场价格行情-每日短讯 2026年6月28日龙门实业(集团)有...
2026年6月28日龙门实业(集团)有限公司西三街农副水产品市场价格行情-每日短讯 2026年6月28日龙门实业(集团)有... -
 快资讯丨为什么续保要重视保障期限? 在保险领域,续保是一个关键环节,...
快资讯丨为什么续保要重视保障期限? 在保险领域,续保是一个关键环节,...